3D Scene 정보를 바탕으로 사용자가 자연어로 질문을 하면 답변을 하는 동시에 해당되는 물체를 찾아주는 ScanQA 모델을 개발하였다. 이 모델의 개발을 위해서 ScanNet 데이터와 QA pair가 결합된 ScanQA데이터셋도 새로 생성하고 공개하였다.

ScanQA Dataset
기존에 존재하던 3D-QA 데이터셋들이 템플릿으로 질문/대답이 이루어지는 반면에 ScanQA에서는 자연어 질의응답으로 데이터가 구성된다. (템플릿방식: (MT-EQA )“Does <OBJ1> share same color as <OBJ2> in <ROOM>?”과 같이 정해진 형태에 단어만 갈아끼우는 방식) ScanRefer에서는 하나의 타겟 오브젝트에 대한 QA만 가능했지만 ScanQA에서는 여러 물체에 대한 질문도 가능하다.

데이터셋 생성 방식
- ScanRefer에 각 오브젝트별로 달려있는 Caption을 T5모델에 넣고(Text-to-text 모델) 돌려 Seed question 생성
- Amazon Turk를 이용하여 사람들을 고용한 후 필터링
- 질문을 4개 카테고리로 나누어 사람들에게 평가하게 함 (Valid / Too easy / Unanswerable / Unclear)
- 각 질문별로 3명 중 2명 이상이 Valid로 평가한 질문만 수집
- 답변을 받기 전, 질문을 수정해야 할 것 같으면 질문을 수정하게 함.
- 답변은 사람들이 자유롭게 작성하도록 함. (Scene에 기반하지 않았다고 생각되어 자동생성 답변은 쓰지 않음)
데이터셋 통계
- 총 41,363개의 질문 (32,337개의 서로 다른 질문)과 58,191개의 답변 (16,999개의 서로 다른 답변)을 수집하였다. 기존 데이터셋이 수백~수천개였던 것에 비하면 규모가 아주 커진 것이라고 함.
- ScanRefer의 Training/Val/Test split을 따라서 데이터셋을 생성하였는데, ScanRefer의 Test split에서 Object id가 공개되지 않아 Val set을 추가로 둘로 쪼개었다고 한다.
- "Where is ..." 와 같은 질문에는 답변이 다양할 수가 있어서 Image captioning의 Eval metric을 사용했다고 함.
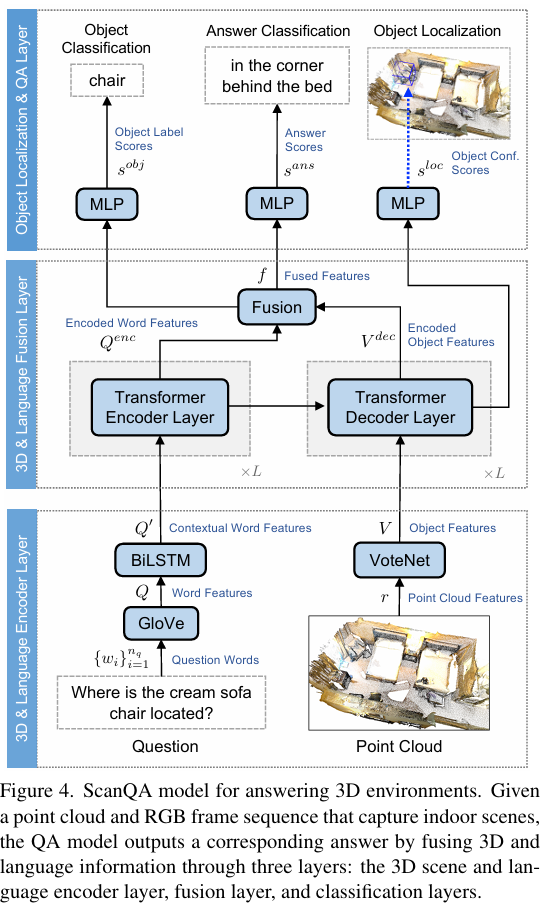
ScanQA Model
3D Feature representation
Point cloud에 Height of the point, Colors, Normals, Multiview image features 등을 붙여서 135차원 벡터로 만듦.
3D & Language encoder layer
- Language: Question을 Word 단위로 분해한 뒤, GloVe를 통과시켜 embedding을 얻고, BiLSTM을 통과시켜 contextualized word represention을 얻는다.
- Point cloud: Votenet을 통과시켜 256개의 Object proposal을 얻는다.
3D & Lanuage fusion layer
- Deep modular fusion network (MCAN)을 사용하여 Fusion 수행.
- Language쪽은 Transformer Encoder 통과시키고, Object proposal쪽은 Transformer Decoder를 통과시키되, Language쪽 정보와 Cross attention.
- 이렇게 얻은 Lanugage-3D 정보를 Attention-MLP를 통해 퓨전하여 fused feature f 생성
Object localization & QA layer
- Object localization module: Transformer decoder에서 나온 Object proposal별로 질문에 해당하는지 여부를 Confidence로 나타내게 함. 학습은 정답지와 CrossEntropy loss를 이용
- Object classification module: fused feature f로부터 2개의 MLP를 통과시켜 답변에 해당하는 Object class (ScanNet에서 주로 사용되는 18개의 클래스) 가 무엇인지 에측하도록 하고 CrossEntropy loss를 이용하여 학습.
- Answer classification module: fused feature f로부터 MLP를 통과시켜 n_a개의 답변 중 정답을 예측하도록 학습. Cross Entropy loss 이용.
- Loss 계산: 위 3개의 모듈에서 나온 Loss와 VoteNet의 object detection loss를 추가하여 최종 Loss 결정.
Experiments
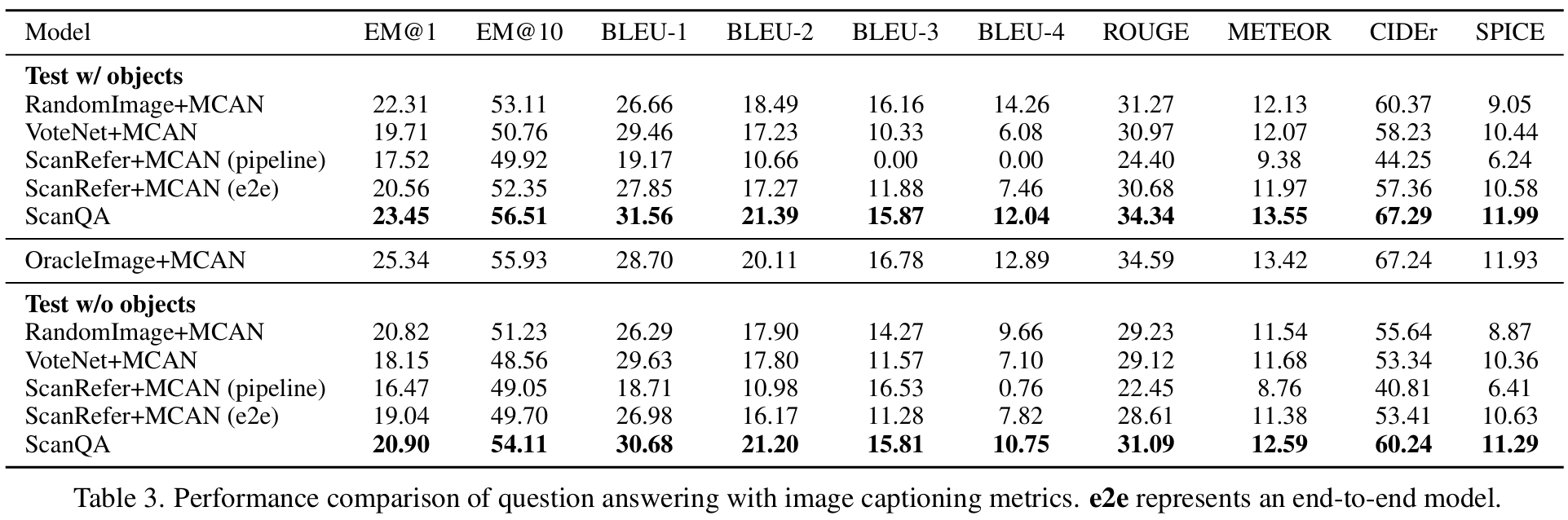
성능 비교
새로 데이터셋을 생성하였기 때문에 비교할만한 이전 연구가 마땅치 않아서, Baselines를 자체적으로 만들었다.
- RandomImage + MCAN: 3장의 RGB 이미지를 랜덤하게 추출한 후 MCAN이라는 VQA를 돌려서 답변 얻음.
- OracleImage + MCAN: 정답 근처에 있는 3장의 RGB 이미지를 랜덤하게 추출한 후 MCAN을 돌려서 답변 얻음.
- VoteNet + MCAN: VoteNet으로 Object와 Feature를 뽑고 이걸 MCAN에 넣어 답변 얻음.
- ScanRefer + MCAN (pipeline): ScanRefer를 이용하여 Object의 위치를 찾고, MCAN을 통과시켜 답변 얻음. 이때 ScanRefer와 MCAN은 따로따로 학습된 걸 사용
- ScanRefer + MCAN (end-to-end): 바로 위 항목과 같지만, 통합 모델에 대해 학습 수행.
어떤 메트릭으로 보더라도, Baseline대비 가장 좋은 성능을 보여주었다. OracleImage + MCAN보다는 성능이 낮은 것으로 나왔다. 답을 어느 정도 알려주고 한 거니까 그렇다고 하는데, 그래도 2D 정보만 가지고 하는 건데 3D 모델의 성능이 더 낮은 것은 개선의 여지가 있어 보인다.
(test w/ objects와 test w/o objects는 어떻게 다른지는 설명을 못찾겠음.)
Ablation studies
처음 입력으로 들어가는 Point cloud에 어떤 정보들을 포함하는게 좋은지 실험해본 결과이다. 이 연구에서 수행한대로 xyz 좌표, Multiview image features, Normals까지 모두 더해주는 게 가장 성능이 좋았다. 그렇지만 생각보다 성능 향상폭이 크지는 않아서 좀 더 연구해볼 필요가 있다고 한다.

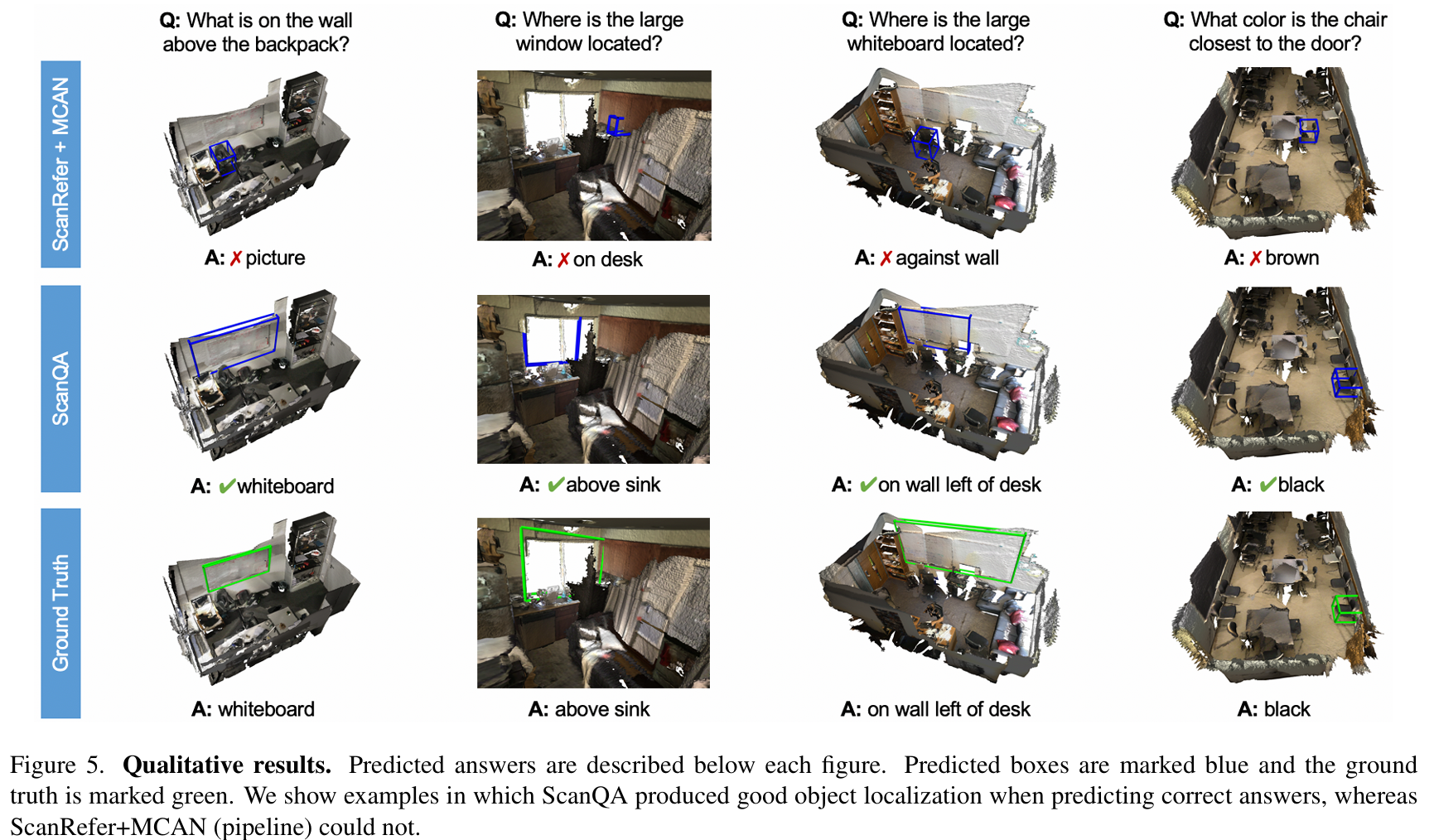
Qualitative Analysis
샘플 몇 개에 대해서 ScanRefer + MCAN (pipeline)과 ScanQA를 비교해 본 결과이다. ScanRefer + MCAN (pipeline)은 전체적인 맥락을 잘 못 읽고, 오브젝트를 잘못 찾는 경우가 많은데, ScanQA는 문장을 잘 이해하고 정확한 답을 내준다.
3D + Language쪽으로 성능을 평가해볼 수 있는 데이터셋이 제공되었다는 부분에서는 좋은 연구이다. 모델 부분은 좀 올드한 감이 있는데, 데이터셋 논문이니까 그걸 감안해야 할 것이다. 비슷한 데이터셋이 있는지, 또 해당 데이터셋을 이용하는 연구는 어느 정도로 진행이 되었는지 추가적으로 조사를 해봐야겠다.



