6D Pose estimation 중 초기 자세 추정 (Coarse pose estimation)에 관한 논문으로 빠른 inference speed와 Detection/Segmentation 에러에 강건하다는 점을 장점으로 소개하고 있다.
아래는 대표 그림인데, 빠른 Inference 속도와 Occlusion이 있는 상황에서도 정확한 추정이 가능한 점이 눈에 띈다.

Methods
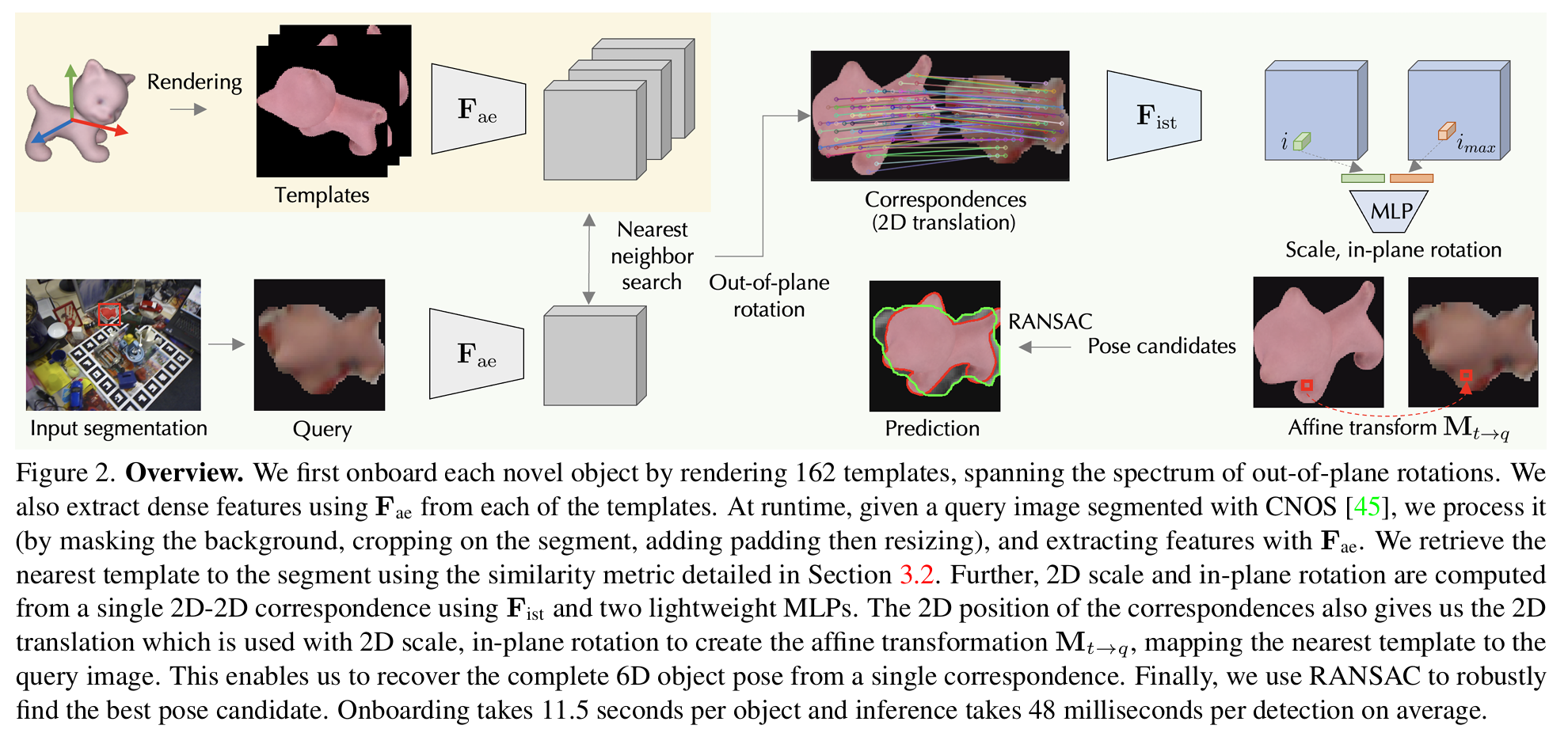
Generating templates
처음에 생성되는 템플릿의 갯수를 줄이기 위하여, 6DoF Object pose는 out-of-plane rotation, in-plane rotation, 3D translation으로 나누어서 접근하였다. 템플릿은 out-of-plane rotation을 정확하게 추정하는데 초점을 맞추어 생성하였고, 결과적으로 162개의 템플릿을 생성하였다.
Predicting Azimuth and Elevation
우선적으로 Out-of-plane rotation을 먼저 추정한다. (Azimuth and Elevation) Azimuth와 Elevation이 무엇인지는 아래 그림을 보면 쉽게 이해할 수 있을 것 같다.

Training the feature extractor F_ae
템플릿과 매칭되는 out-of-plane rotation을 잘 추정하기 위하여 feature extractor F_ae를 이용하였다. F_ae는 Contrastive learning 방법을 이용하여 특별한 방식으로 학습시킨다.

1. 먼저 3D model을 하나 준비한 후 같은 out-of-plane rotation을 갖되, 서로 다른 in-plane rotation, scale, 2D translation을 갖도록 한 쌍의 이미지를 준비한다. (Query / Template image)
2. 조금 더 변화를 주기 위해 Color augmentation, Random cropping 등도 추가로 수행한다.
3. 2개의 이미지를 F_ae를 통과시켜 14 x 14 패치를 2개 얻는다. 각각 q_k, t_k라고 하겠다.
4. q_k의 하나의 패치에 대응되는 t_k의 패치가 있을 텐데, 이 Pair는 Positive로 본다. (2D-2D correspondence)
5. 나머지 패치들은 모두 Negative pair로 본다.
6. 같은 배치 안에 있지만 다른 원본 이미지에서부터 변형되었거나, 다른 Out-of-plane rotation에서 온 것들도 모두 Negative pair이다.
7. InfoNCE loss를 이용하여 F_ae를 학습시킨다. 수식으로 표현하면 아래와 같다.
(t^i*는 q^i에 대응되는 패치를 의미. m_Qk는 각 이미지에 존재하는 Foreground patch(배경이 아닌 실제 물체가 있는 패치)의 갯수)

F_ae는 DINOv2를 기반으로 파인튜닝하였다.
Azimuth and elevation prediction
실제 적용시 Query image에 대해서 Template 중 가장 유사한 이미지를 찾아야 한다. 이 절차는 아래와 같다.
1. 먼저 Query / Template image를 F_ae를 통과시켜 feature를 얻는다. (q, t)
2. q와 t의 각 패치(q^i, t^j)에 대해 Template 중 가장 유사한 패치를 Nearest neighbor 방식으로 찾는다. 이때, Foreground mask를 적용하여 물체가 있는 부분의 패치만 대상으로 한다. 수식으로 나타내면 아래와 같다. 또한 Outlier의 영향을 최소화하기 위해서 score가 0.5 이상일 경우만 고려한다.

3. q와 t의 최종 similarity는 아래의 수식으로 결정한다: q^i의 각 패치별에 대해 가장 비슷한 템플릿의 패치 t^(i_max)들을 찾고, 이에 대한 Score를 가중평균한다.

4. 모든 템플릿에 대해 similarity를 계산한 후, 가장 similiarity가 높은 템플릿을 out-of-plane rotation으로 결정한다.
Predicting the remaining DoFs
이제 Out-of-plane rotation을 찾았으니 나머지 4개의 DoFs을 찾아야 한다. 즉 아래 Affine transformation의 파라미터인 s, α, t_x, t_y (Scale, In-plane rotation, 2D translation)를 찾아야 한다.

t_x, t_y는 앞에서 구한 2D correspondence로부터 구할 수 있다: {(i, i_max)}
나머지 s, α 를 구하기 위해 새로운 Feature extractor F_ist를 도입하였다. 앞에서 사용했던 F_ae를 쓰면 안되는 이유는 F_ae는 Scale과 in-plane rotation이 달라지더라도 비슷한 Feature가 나오도록 학습시켰기 때문이다.
Query와 Template에서 대응되는 pair들을 F_ist를 통과시킨뒤, 최종적으로 MLP를 통과시켜 s, α 를 추정하도록 하였다. 이 네트워크는 아래의 Loss를 이용하여 학습시킨다.
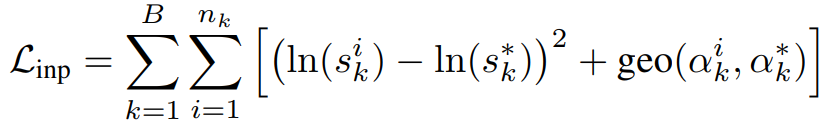
*가 붙은 것은 Ground Truth를 지칭하고, geo는 geodesic loss를 의미하고, 아래와 같은 수식으로 계산된다.

F_ist는 ResNet18 기반의 모델을 선택하였다고 하였다. DINOv2와 같은 최신 모델들은 Scale이나 In-plane rotation이 있어도 비슷한 Feature가 나오기 때문이라고 한다.
RANSAC based Affine transformation estimation
마지막으로 각 템플릿에 대해 RANSAC을 적용하여 가장 많은 inlier가 나오는 템플릿을 선택한다. (Out-of-rotation을 구할 때 후보가 여러개가 나올 수 있는데, 이중에서 어떤 것을 고를지 정할 때 RANSAC을 쓴다는 의미로 생각된다.)
Experiments
Comparison Results on BOP datasets

위 테이블에서 여러 데이터셋에 대해서 AR (average recall)을 비교하였다. 먼저 Coarse pose estimation을 하는 연구들인 ZS6D, MegaPose와 비교하였다. (Row 3,4,5) 성능은 6 정도 더 높으면서도 Runtime이 많이 줄어든 점을 확인할 수 있다.
또한 여러 Refinement를 적용한 경우에도 성능이 높으면서 Runtime이 짧아짐을 볼 수 있다. Coarse pose estimation이 좋으므로 어찌 보면 당연한 결과인 것으로 보인다. (Runtime 차이도 대부분 Corase pose estimation에서의 Runtime 차이에 기인)
Qualitative results
아래 그림은 실제 샘플 이미지에 대한 Pose estimation 결과이다. 맨 왼쪽은 GT / CNOS 결과이고, 2번째 컬럼은 Mega pose결과, 3번째 컬럼은 Gigapose의 결과이다. 아래 히트맵에서 보면 Gigapose가 좀 더 어두운 색깔, 즉, 더 에러가 더 작다는 것을 알 수 있다. 특히나 Megapose는 하나를 거의 빼먹다시피 했다.
4,5번째 컬럼은 Refinement를 한 이후의 결과 비교인데, 여기서도 Gigapose의 에러가 더 작게 나타나는 것을 확인할 수 있다.

Accuracy with Wonder3D
하나의 Reference image를 Wonder3D에 넣고, 이로부터 나온 3D reconstruction model을 이용하여 Pose estimation을 수행하였다. 또 다른 토픽은 Model-free를 염두에 둔 분석인 듯 하다.

Row1/2: CNOS에 GT 3D model을 쓰고, MegaPose/GigaPose는 Wonder3D의 결과를 사용한 결과이다. 마지막 컬럼은 MegaPose/GigaPose에 GT 3D model을 쓰고 Refinement는 하지 않은 결과이다.
Row3/4: CNOS에도 Wonder 3D의 결과를 사용한 결과이다.
Row4의 Single image - refined가 model-free에서의 최종 결과가 될 것 같은데, 그래도 여전히 Model-based refined보다는 한참 떨어지는 결과로 보인다. Row2/4를 비교해 보면 모델이 있을 때와 없을 때 CNOS 결과는 엇비슷하게 나오는데, Coarse 성능은 많이 벌어지는 점이 눈에 띈다.
Runtime
Megapose와 런타임을 비교해 보면, 템플릿의 갯수가 훨씬 적고, 연산도 가벼워서(Image level vs Patch level) Coarse pose에서의 속도 차이가 많이 난다. 다만 Onboarding은 Gigapose가 훨씬 오래 걸린다. 아마 Feature를 생성해야 하기 때문인 듯 하다.

Robustness to segmentation error
아래 그래프에서 CNOS의 segmentation error에 따라 MegaPose/GigaPose의 성능이 어떻게 달라지는지를 표시하였다. T-Less/YCB-V 데이터셋에서 GigaPose는 Segmentation error에 상관없이 좋은 성능을 보이지만, MegaPose는 Segmentation 성능에 많이 좌우되는 것을 확인할 수 있다. 다만 LM-O에서는 MegaPose/GigaPose가 비슷한 양상을 보인다. 저자들은 Occlusion이 많고 작은 물체가 많기 때문이라고 설명한다.

Ablations

Row1: F_ae를 파인튜닝하지 않고 사용한 결과이다. 성능이 많이 하락함을 볼 수 있다.
Row2: In-plane rotation까지 템플릿으로 만들어서 사용한 결과이다. (F_ist를 이용한 Affine transformation을 대체) 성능이 5.8% 가량 하락한다.
Row3/4: PnP를 여러가지로 바꿔서 해 본 결과이다. 3D-to-2D 또는 n의 개수를 늘려서 해 보았지만 성능이 더 안좋게 나왔다.
Row5: 최종 결과
Row 6: 템플릿 갯수를 576개로(MegaPose와 동일하게 맞춰서) 늘려서 해본 결과이다. 성능이 소폭 상승한다. 그럼에도 이것을 최종 결과로 하지 않은 이유는 Onboarding에서의 런타임이나 메모리 이슈 때문인 것으로 보인다.
6 DoFs pose estimation을 하는 전체적인 흐름은 여러 연구들이 다 비슷비슷한 것 같다. GigaPose에서는 Coarse pose estimation을 할 때 vision model을 적극적으로 활용해서 Feature level에서의 비교를 함으로써 좀 더 좋은 성능/빠른 런타임을 가져올 수 있었다.



