요약
여러 branch를 갖는 diverse branch block으로 학습을 한 뒤, Inference 시에는 KxK kernel로 대체하여 효율성을 높였다. Diverse branch는 KxK kernel로 변환이 가능한 형태들을 조합하여 만들었다.
방법론 설명
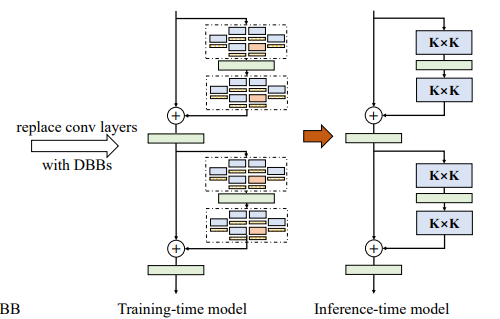
아래 그림에서와 같이 트레이닝시에는 왼쪽과 같이 여러 Branch를 가지도록 하고, Inference 시에는 오른쪽 그림과 같이 단순한 구조로 바꿔준다.


여러 Block을 보면 아래와 같은 구조가 된다.
아래 그림과 같이 각 Branch에 사용할 수 있는 후보군은 총 6개를 고려하였고, 각각은 모두 KxK kernel로 치환할 수 있음을 설명하고 있다.

실험 결과
CIFAR-10 / CIFAR-100 / ImageNet에서 DBB를 활용하면 성능을 향상시킬 수 있음을 확인하였다. 위에서 설명하였듰이 Inference시에는 Original model의 구조와 동일하게 돌려놓을 수 있으므로 (즉, KxK kernel의 형태), 추가적인 cost 없이 성능향상을 이뤘다고 할 수 있다.

Downstream task인 Object detection과 Semantic segmentation에서도 성능 향상이 있음을 보이고 있다.

아래 그림에서는 BN layer의 scaling factor 크기 비교를 통해 어떤 branch가 중요한 역할을 하는지 살펴보고 있다. 예를 들어 (b)와 (c)를 비교해 보면 stride-2 layer에서는 1x1 - AVG branch가 보다 중요한 역할을 하는 것을 확인할 수 있다.

아래 표는 ResNet-18, ImageNet 데이터를 가지고 각 Branch를 넣었다 뺐다 하면서 실험해 본 결과이다.

위 표의 몇가지 세팅을 그림으로 나타내면 아래와 같다.

위 실험 결과에서 몇 가지 눈여겨 볼 만한 사항은 다음과 같다.
- 두 개의 KxK를 사용하는 것보다 (Double Duplicate, 10번째) KxK 와 1x1를 같이 사용하는 것이(6번째) 더 효과가 좋았다. 두 개의 KxK를 사용하는 것이 Capacity는 더 클 것이지만, 큰 Capacity와 작은 Capacity를 섞어서 사용하면 시너지가 있는 것으로 보인다. Triple duplicate와 3개의 Branch를 섞어서 쓰는 경우를 비교해 보더라도 마찬가지의 결과를 관측할 수 있다.
- Purely linear DBB의 경우(BN layer를 addition 뒤에 하나만 배치) 성능 향상이 그닥 크지 않았다. Nonlinearity 없이도 DBB가 성능 향상을 불러올 수는 있지만, Non-linearity를 포함하는 것이 보다 최적임을 보여준다.



